The term fragmentation is IMHO the best word to describe wayland. And that’s the reason why this page exists. While traditional “three lines” (XMODIFIERS, GTK_IM_MODULE, QT_IM_MODULE) also mostly work under wayland, but there is some other way to setup and special care needed to make all application works.
As an Linux application developer, one might not aware that there could be certain effort required to support Input Method (or Input Method Editor, usually referred as IME) under Linux.
What is input method and why should I care about it?
Even if you are not aware, you are probably already using it in daily life. For example, the virtual keyboard on your smart phone is a form of input method. You may noticed that the virtual keyboard allows you to type something, and gives you a list of words based on what you already partially typed. That is a very simple use case of input method. But for CJKV (Chinese, Japanese, Korean, Vietnamese) users, Input method is necessary for them to type their own language properly. Basically imagine this: you only have 26 English key on the keyboard, how could you type thousands of different Chinese characters by a physical keyboard with only limited keys? The answers, using a mapping that maps a sequence of key into certain characters. In order to make it easy to memorize, usually such mapping is similar to what is called Transliteration , or directly use an existing Romanization system.
For example, the most popular way for typing Chinese is Hanyu Pinyin.
In the screenshot above, user just type “d e s h i j i e”, and the input method gives a list of candidates. Modern Input method always tries to be smarter to predict the most possible word that the user wants to type. And then, user may use digit key to select the candidate either fully or partially.
What do I need to do to support Input method?
The state of art of input method on Linux are all server-client based frameworks. The client is your application, and the server is the input method server. Usually, there is also a third daemon process that works as a broker to transfer the message between the application and the input method server.
1. Which GUI toolkit to use?
Gtk & Qt
If you are using Gtk, Qt, there is a good news for you. There is usually nothing you need to do to support input method. Those Gtk toolkit provides a generic abstraction and sometimes even an extensible plugin system (Gtk/Qt case) behind to hide all the complexity for the communication between input method server and application.
The built-in widget provided by Gtk or Qt already handles everything need for input method. Unless you are implementing your own fully custom widget, you do not need to use any input method API. If you need your custom widget, which sometimes happens, you can also use the API provided by the toolkit to implement it.
The best documentation about how to use those API is the built-in widget implementation.
SDL & winit
If you are using SDL, or rust’s winit, which does have some sort of input method support, but lack of built-in widget (There might be third-party library based on them, which I have no knowledge of), you will need to refer to their IME API to do some manual work, or their demos.
Refer to their offical documentation and examples for the reference:
As for XCB, you will need to use a third-party library. I wrote one for XCB for both server and client side XIM. If you need a demo of it, you can find one at:
As for writing a native wayland application from scratch with wayland-client, then you will want to pick the client side input method protocol first. The only common well supported (GNOME, KWin, wlroots, etc, but not weston, just FYI) one is:
If you use a toolkit with widget that can already support input method well, you can skip this and call it a day. But if you need to use low level interaction with input method, or just interested in how this works, you may continue to read. Usually it involves following steps:
Create a connection to input method service.
Tell input method, you want to communicate with it.
Keyboard event being forwarded to input method
input method decide how key event is handled.
Receives input method event that carries text that you need to show, or commit to the application.
Tell input method you are done with text input
Close the connection when your application ends, or the relevant widget destructs.
The 1st step sometimes contains two steps, a. create connection. b. create a server side object that represent a micro focus of your application. Usually, this is referred as “Input Context”. The toolkit may hide the these complexity with their own API.
Take Xlib case as an example:
Create the connection: XOpenIM
Create the input context: XCreateIC
Tell input method your application wants to use text input with input method: XSetICFocus
Key event is forward to input method by compositor, nothing related to keyboard event need to be done on client side.
Get committed text zwp_text_input_v3.commit_string
Call zwp_text_input_v3.disable
Destroy relevant wayland proxy object.
And always, read the example provided by the toolkit to get a better idea.
3. Some other concepts except commit the text
Support input method is not only about forwarding key event and get text from input method. There are some more interaction required between application and input method that is important to give better user experience.
Preedit
Preedit is a piece of text that is display by application that represents the composing state. See the screenshot at the beginning of this article, the “underline” text is the “preedit”. Preedit contains the text and optionally some formatting information to show some rich information.
Surrounding Text
Surrounding text is an optional information that application can provide to input method. It contains text around the cursor, where the cursor and user selection is. Input method may use those information to provide better prediction. For example, if your text box has “I love |” ( | is the cursor). With surrounding text, input method will know that there is already “I love ” in the box and may predict your next word as “you” so you don’t need to type “y-o-u” but just select from the prediciton.
Surrounding text is not supported by XIM. Also, not all application can provide valid surrounding text information, for example terminal app.
Reporting cursor position on the window
Many input method engine needs to show a popup window to display some information. In order to allow input method place the window just at the position of the cursor (blinking one), application will need to let input method know where the cursor is.
Notify the state change that happens on the application side
For example, even if user is in the middle of composing something, they may still choose to use mouse click another place in the text box, or the text content is changed programmatically by app’s own logic. When such things happens, application may need to notify that the state need a “reset”. Usually this is also called “reset” in the relevant API.
$ [12752:12787:1013/110502.625383:ERROR:bus.cc(399)] Failed to connect to the bus: Could not parse server address: Unknown address type (examples of valid types are "tcp" and on UNIX "unix") [12752:12787:1013/110502.625545:ERROR:bus.cc(399)] Failed to connect to the bus: Could not parse server address: Unknown address type (examples of valid types are "tcp" and on UNIX "unix")
TL;DR: this is not considered as a user facing change.
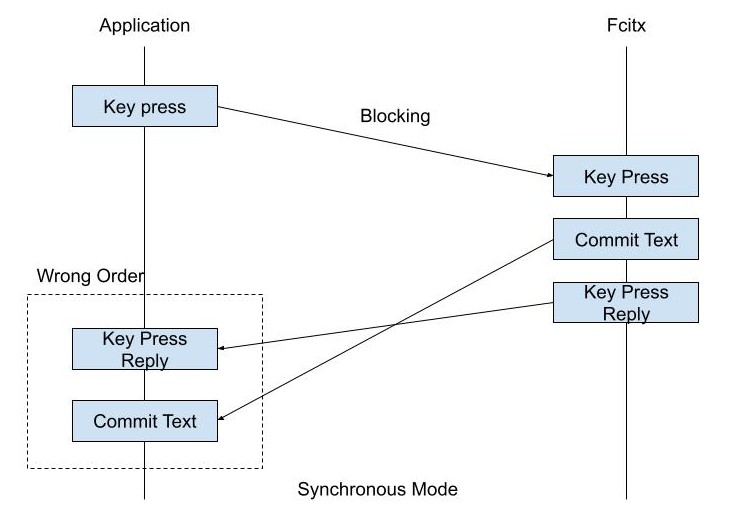
In a previous post, we discussed the issue between the input method event order and the blocking dbus call. To put it simple, input method may generate multiple different outcomes from a single key press, such as committing text, set preedit, etc. The key press comes as a Inter-process communication(IPC) from an application to Fcitx.
If this IPC is blocking, then the event can only arrive after the call is done. Previously, we tried to always use async call to ensure the event happens before the reply is delivered to application first. This can’t be used for Gtk 4 GtkIMContext anymore. Gtk 4 hides too much API comparing to Gtk3, which prevents us from doing a lot of things, for example, re-inject the key event into the application.
In the old async mode, the key event will always be filtered by Fcitx IM Context, then re-inject into the application when the result of event handling returns. Upon the result is received, Fcitx IM Context will copy the GdkKeyEvent back into the application with a special flag on the modifier, to prevent it from being handled by Fcitx IM Context again.
In Gtk 4, there is no API to create a synthetic key event (which is problematic for some other features that Fcitx supports, but we will not discuss that here), which means we will need to implement using the synchronous mode anyway.
Well, not really “must”, because I do find some API to allow a hacky asynchronous implementation, by memorizing the pointer address of GdkEvent and use gdk_put_event to reinject the event. Though that doesn’t work for chromium code because it doesn’t use gdk for event handling.
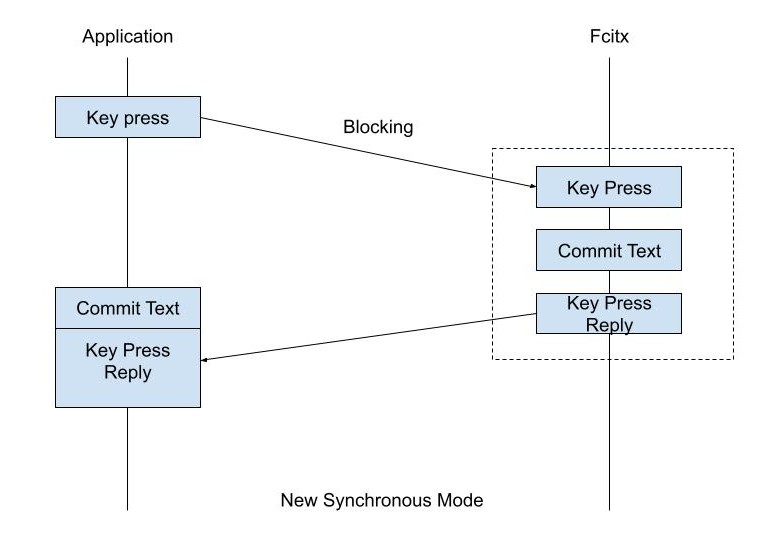
So what we can do here? The answer is, we create a new version of ProcessKeyEvent API, ProcessKeyEventBatch.
In the old synchronous mode, the root cause of wrong event order is the event sending from input method can only be handled “after” the synchronous ends, which is not we want to see.
In the new ProcessKeyEventBatch, what we do is we do not send the event from input method to application immediately. We block the sending procedure on the input method side until the reply happens. When the reply is finally being sent, Fcitx will put all the events that need to be handled by application in the reply.
Say, application want to commit some text before the key event is handled by application. After commitString() is called on the input method side, the CommitString dbus signal doesn’t happen in the new mode, instead, we wait and put them together in the return value of “ProcessKeyEventBatch”. Upon receiving the reply, the FcitxIMContext first decodes the reply to see if there is anything piggybacked in the same reply, and handles them first. This will make the event order consistent on both of the input method side and the application side.